
EMS High Availability (HA) concepts
FortiClient EMS HA offers redundancy at both the application and database levels:
-
EMS application HA—Two or more EMS nodes connect to the same database which can be a standalone PostgreSQL server or a list of PostgreSQL servers (DB nodes in short) that are part of a cluster.
-
PostgreSQL DB HA—EMS connects to a list of PostgreSQL servers (DB nodes in short) that are part of a cluster.
Topology
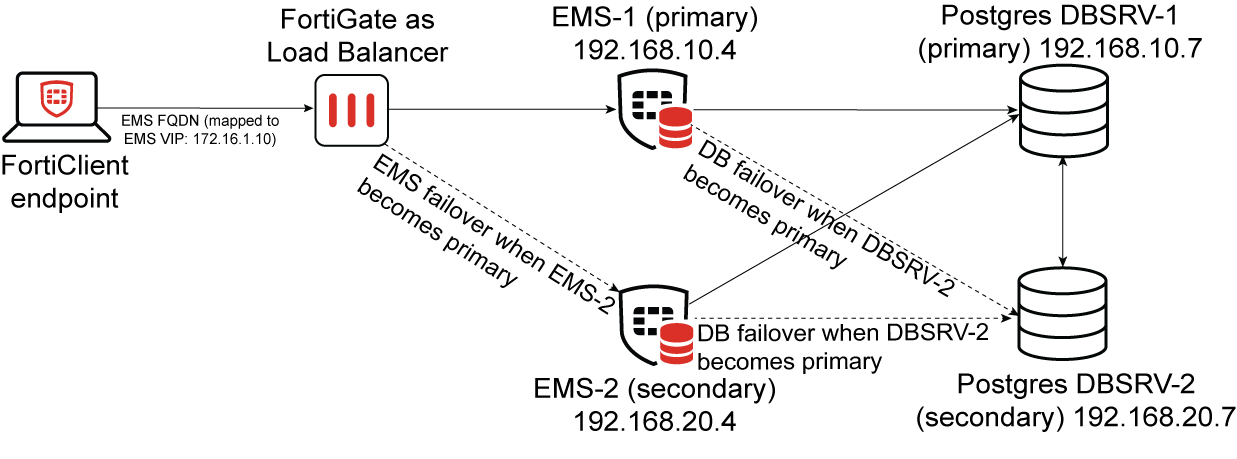
EMS application HA
An EMS HA cluster can be formed when two or more EMS nodes connect to the same database, which can be a standalone PostgreSQL server or a list of PostgreSQL servers (DB nodes) that are part of a cluster. EMS supports only active-passive HA mode, where the first installed EMS node will be the primary and all subsequent EMS nodes will join the cluster as secondary or secondary nodes.
When deployed in HA mode, each EMS node registers itself in a database table where the node information gets recorded and in return gets all its configuration through the database which is shared across all nodes. There is no concept of "EMS node syncing" as all nodes get to look at the same data and configuration by using the same database and are therefore, always up to date.
The EMS primary node runs all EMS services and is the only node capable of receiving requests from endpoints. Whereas on the secondary nodes, only a few services run to perform a heartbeat for the node and to take action when the primary node becomes unavailable.
Each EMS node is assigned a random non-configurable priority value when joining the EMS cluster. When the primary node becomes unavailable, it stops performing its periodic heartbeat on the cluster registration database table. After a timeout, the secondary node with the highest priority that is currently online will be promoted to primary. The new primary node automatically starts up all services and will be able to receive traffic.
By default, each EMS node sends a heartbeat signal every 10 seconds. This interval can be configured using the High Availability Keep Alive Interval option (default is 10 seconds) in the EMS Settings page. When an EMS node does not send a heartbeat for more than twice the duration of the configured interval, that node is considered unavailable. If it is the primary up to that point, a new node will be promoted as the primary within up to another 60 seconds.
As only one EMS node is active at any given time while the remaining nodes are in standby mode, the sizing and capacity guidelines for managed endpoints (including CPU and RAM requirements per endpoint) in an EMS HA cluster are the same as for a single EMS instance, regardless of the number of EMS nodes in the HA cluster. See Management capacity in the EMS Administration Guide for details.
PostgreSQL DB HA
EMS uses postgreSQL as a relational database, which is highly customizable and one of the most popular open-source databases. It is not a Fortinet product, nor supported by Fortinet.
You can configure EMS to connect to a standalone PostgreSQL server or a list of PostgreSQL servers (DB nodes) that are part of a cluster for better redundancy. When deployed in an HA cluster, PostgreSQL uses an addon, repmgr (Replication Manager) to replicate data from the primary node to the secondary nodes. The repmgr extension is also an open-source tool, and is not supported by Fortinet.
EMS requires a custom PostgreSQL extension to function. While instructions to install that extension are provided, we provide an EMS PostgreSQL HA repmgr custom docker image where that custom extension is already installed and ready for EMS. This image is further customized by Fortinet to include additional node reconciliation scripts to add another layer of protection and prevention of split brain. For this image, Fortinet provides support for matters related to replication, failover, split-brain and syncing between nodes but not for anything related to the database itself (PostgreSQL), docker, the host OS where the container runs on or network issues in the infrastructure that the cluster or DB nodes are part of.
When in HA, PostgreSQL only support Active-Passive mode where all secondary nodes are available in read-only mode and all connect to the primary node to replicate data from it using the repmgr addon. When the primary node becomes unavailable, the secondary nodes go into election to choose the new primary. The selection is based on the secondary node's individual priorities defined when setting up the cluster and needs to be agreed upon by a majority of secondary nodes. For a secondary node to be promoted to primary, it requires quorum of (n/2)+1, where n is the number of nodes in the cluster. This needs to be taken into account when setting up the PostgreSQL cluster to prevent a lock down where no other node can become a primary.
To prevent split brain scenarios where, due to communication loss, a node may think it needs to promote itself to primary while the primary is actually still active, additional special nodes (called witness) can be added to help form a stronger quorum. While the witness nodes are part of the cluster, they do not take part in the data replication and are there only to monitor and vote on node promotion in case of failover.
The recommended number of nodes for a single region PostgreSQL HA cluster for a small cluster is 3 (2 DB nodes + 1 witness node). For a medium cluster, 5 (3 DB nodes + 2 witness nodes). For a large cluster, 9 (7 DB nodes + 2 witness nodes).
For EMS, the small cluster size is enough. The medium and large size should be used only depending on strong high availability requirements and infrastructure, but the larger the cluster, the more complex it is to setup and maintain. PostgreSQL with repmgr do provide Geo Redundancy support, but neither offer nor recommend automatic failover across regions.
When EMS connects to a PostgreSQL cluster, it connects and monitors a list of data nodes every 10 seconds to check which node is read-write (the primary). When there is a failover, EMS will check all the PostgreSQL DB nodes it knows of and will self update its configurations to point to the new primary.
The setup with the provided docker images is complex. They simplify the setup in most cases and sets up the recommended tools to make the cluster work, but are complex to maintain. It is recommended to deploy your own PostgreSQL cluster using a cloud service or setting up PostgreSQL nodes directly if you have of DBAs to maintain it. The table below compares these options in terms of support provided by Fortinet:
| Cloud-managed PostgreSQL | Self-setup PostgreSQL | Fortinet-provided standalone Docker image | Fortinet-provided HA docker image | |
|---|---|---|---|---|
| OS upgrades | No | No | No | No |
| PostgreSQL patching | No | No | Yes | Yes |
| Data backup / restore | No | No | No | No |
| Data storage | No | No | No | No |
| Docker daemon | - | - | No | No |
| EMS SQL errors related to data encryption | No | Yes | Yes | Yes |
| Server migration | - | No | No | No |
| Data replication | No | No | - | Yes* |
|
* Fortinet is only responsible for issues related to the monitor script shipped in the images and to ensure no customization-related issues are there. Most of the cases will be issues with |
||||
See EMS HA deployment options for a list of HA deployment options and detailed instructions for each scenario.