




FAQ
How to handle false positives for ML Based Anomaly Detection?
There are two svm-types: standard and extended. If standard is selected, the system automatically disables the svm models which can easily trigger false positives. If extended is selected, the system enables all svm models.
So when you find unexpected false positives, please just leave svm-type as standard (By default).
Which content-types are supported by ML?
Support list:
-
multipart/related
-
application/soap+xml
-
text/xml, application/xml, application/vnd.syncml+xml, application/vnd.ms-sync.wbxml
-
multipart/form-data
-
text/html
-
application/x-www-form-urlencoded
-
text/plain
-
multipart/x-mixed-replace
-
application/rss+xml
-
application/xhtml+xml
-
application/json, text/json
Unsupported:
-
message/HTTP
-
application/rpc
-
application/x-amf
-
application/vnd.syncml+wbxml
Which charset are supported by ML?
FortiWeb machine learning supports most of the popular character sets. You can check with CLI as below:
FortiWeb # config waf machine-learning-policy
FortiWeb (machine-learni~g) # edit 1
FortiWeb (1) # config allow-domain-name
FortiWeb (allow-domain-n~m) # edit 1
FortiWeb (1) # set character-set
AUTO AUTO
BIG5 BIG5
GB2312 GB2312
ISO-2022-JP ISO-2022-JP
ISO-2022-JP-2 ISO-2022-JP-2
ISO-2022-KR ISO-2022-KR
ISO-8859-1 ISO-8859-1
ISO-8859-2 ISO-8859-2
ISO-8859-3 ISO-8859-3
ISO-8859-4 ISO-8859-4
ISO-8859-5 ISO-8859-5
ISO-8859-6 ISO-8859-6
ISO-8859-7 ISO-8859-7
ISO-8859-8 ISO-8859-8
ISO-8859-9 ISO-8859-9
ISO-8859-10 ISO-8859-10
ISO-8859-15 ISO-8859-15
Shift-JIS Shift-JIS
UTF-8 UTF-8
What are the major specification & limitation of machine learning - Anomaly Detection
1. One server policy can only enable one machine learning policy;
2. One machine learning policy can create one or more domains; no matter how many machine learning policies are enabled;
3. One URL can learn maximum 128 parameters;
4. One domain can learn maximum 1000 parameters;
5. The maximum number of domains is listed as below.
These specs are the result of a comprehensive evaluation based on the memory of the platform. It cannot be changed easily, otherwise there will be a risk of insufficient memory, thereby may affect other normal business forwarding, and there is no workaround for now.
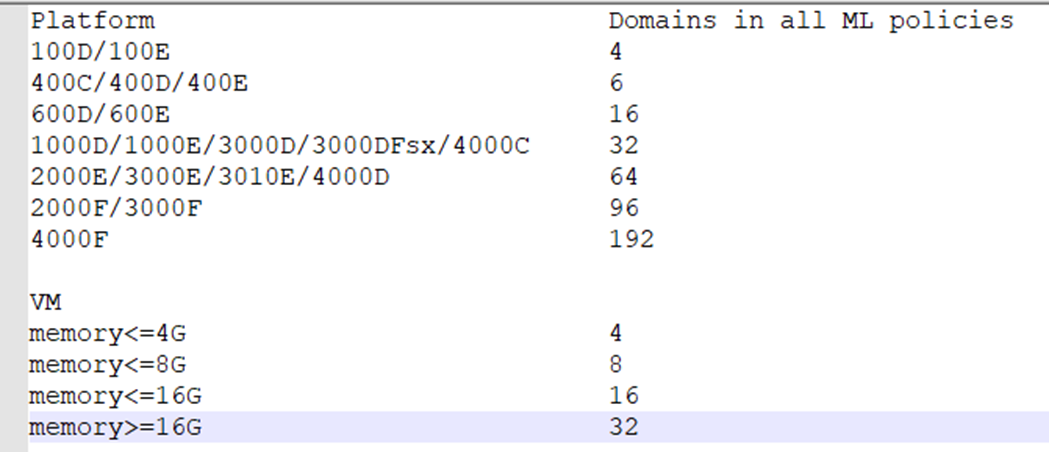
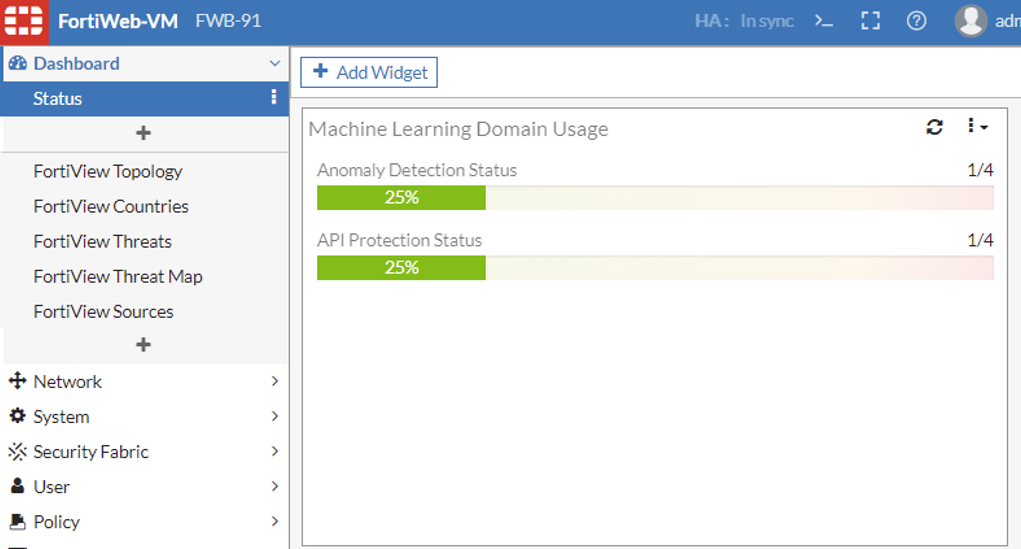
From 7.0.2, the maximum number of domains for Anomaly Detection & API Protection supported by different platforms can be seen via Dashboard > Status > Add Widget > ML Domain Usage.
How to find out the SVM threat model database version?
You can see the version in ‘diag sys update info’. SVM database is included in the general FortiWeb signature database:

Why is machine learning anomaly case-sensitive with URL and parameter name? Can we turn it off?
Machine learning is case-sensitive with URL¶meter name, just because case-sensitive is by default in Linux systems.
No option to turn it off at present.
After how many minutes or hours the “unconfirmed” parameter will be discarded by the garbage collector?
A parameter is in unconfirmed status initially, and it will be set to be Confirmed if the parameter is contained in the requests from a certain number of different source IPs within the given time. Otherwise, the parameter will be discarded.
ip-expire-cnts defines "the number of different source IPs", while the ip-expire-intval defines the given time period.
The valid range for ip-expire-intval is 1-24 in hours, and the default value is 4.The valid range for ip-expire-cnts is 1-5, and the default value is 3.
Is there a way to check how many samples are discarded due to ‘sample-limit-by-ip’ in the machine learning database?
There is no way to check such statistics. Samples exceeding the threshold per 30 minutes will not be collected any more.
This is different from the “Collected Sample” displayed in the Tree View tab. “Collected Samples” means the “effective” samples. For example, when this number reaches 400, machine learning will start to build the initial mode; when it reaches 1200 and find there are a few patterns generated (the model is considered to be stable), machine learning switches to standard mode.
Is Sample Collection mode Extended removed in the 6.4 version? I don’t see it in GUI or CLI configuration
Yes, options to configure sample-collecting-mode are removed from 6.4 GUI & CLI. You can think that the process is similar while some of the modes’ implementation have been changed and simplified – machine learning works in initial mode (like normal or fast mode as in 6.3) at first (when samples reaches the start-min-count, default 400), and will switch to standard mode with more effective samples (when the number of samples accumulates to switch-min-count, default 1200, and switch-percent is smaller than the value you set; please refer to the CLI guide for detailed description).
The 6.3 option “dynamically update when parameters change is enabled” is no longer available in 6.4/7.0. Are there any mechanism changes?
6.4/7.0 machine learning uses different mechanisms to detect changes. The new refreshing mechanism uses a sliding window instead of boxplot to simplify ML.
Related CLI commands are as below; you can also check the detailed meaning in FortiWeb CLI Reference.

How does noisy samples impact machine learning function, and how to alleviate the impact?
If a string is learned during the collecting stage, it’ll not be blocked in the running stage. That’s the difference when using “cmd” and “mode”.
Noisy samples can be detected during the sample collection period. Some samples can be treated as abnormal samples and excluded from the samples used to build the anomaly detection model. However, if such samples account for a large proportion, they’ll usually not be detected as noise.
Another possible way to alleviate this problem is to enable signature profiles. Once a request is blocked by signature, it’ll not be learned as a sample.
Below sections are troubleshooting methods for some typical issues.